DeepSeek Creates Buying Opportunity for Nvidia Stock
January 31, 2025

Beth Kindig
Lead Tech Analyst

DeepSeek caused a deep rout in AI stocks earlier this week with Nvidia erasing more than $600 billion in value; the biggest one-day loss of any company in history. The R&D company out of China stated the model cost $6 million to train, which sent the market into a panic as this is pennies to the dollar compared to what Big Tech is spending. The jerk-reaction readthrough was that, in the blink of an eye, DeepSeek had fundamentally rewritten the AI capex story.
The battle between the United States and China on large language models (LLMs) following DeepSeek’s challenge to OpenAI has been called AI’s Sputnik moment. The most important takeaway for investors about this analogy is that Sputnik spurred massive investments. It was not the final destination, rather, it was the beginning of a multi-decade space race. The Sputnik satellite cost $15 to $20 million or $33 million with cost-adjusted inflation, yet the United States would spend an estimated $1 trillion over a sixty year period in response.
The United States takes it quite seriously to stay in the lead, and AI will spur an arms race unlike anything the world has seen before. Consider that it took sixty years for the government to spend $1 trillion (inflation adjusted) on the space race, yet in one sweeping piece of legislation, the United States will spend $500 billion in 5 years on AI infrastructure, up from $70 billion being spent in 2024 alone.
Remember, it was the market’s so-called “efficiency” that caused Nvidia’s stock to drop 60% from a gaming-related miss following rumors that Ethereum’s merge to Proof-of-Stake (PoS) would be the death knell for the stock. This was the very moment the powerful AI GPUs called Hopper were shipping, equipped with a Transformer Engine that would enable self-learning models, and change the world as we know it.
Tech is defined by disruption, by thousands of product announcements, and by leagues of competitors. It can be a noisy and costly sector when investors get whiplashed by the news of the day. My firm has an enviable track record on Nvidia – including speaking out during staggering selloffs or supply chain rumors. This includes also telling you when we are not buying, or when a stock is frothy, such as when Nvidia was trading in the $140s. We also go to great lengths to tell you when we plan to buy again. You will find dozens (perhaps hundreds) of articles on DeepSeek at this point; yet you will be hard pressed to find one other person helping investors navigate Nvidia’s stock at this granular level.
Below, I provide evidence that DeepSeek is not the black swan that killed Nvidia overnight – in fact, driving down the costs of AI development has always been the plan -- and will ultimately boost Nvidia’s sales in the long run as AI will leave the data center, and move on-premise for enterprises and on-device for consumers.
I also touch base on what investors should keep an eye on price-wise moving forward for the GPU juggernaut.
DeepSeek’s DualPipe Algorithm
DeepSeek’s DualPipe Algorithm optimized pipeline parallelism, which essentially reduces inefficiencies in how GPU nodes communicate and how mixture of experts (MoE) is leveraged. MoE refers to distributing a computational load across “multiple experts” (or neural networks) to train across thousands of GPUs using what is called model and pipeline parallelism. This enables more compute-efficient training yet the parameters still need to be loaded in VRAM, so the memory requirements remain high.
Tom’s Hardware wrote an article about this a month ago, with an usually prescient title: “Chinese AI company says breakthroughs enabled creating a leading-edge AI model with 11X less compute — DeepSeek's optimizations could highlight limits of US sanctions.” The article stated: “The DualPipe algorithm minimized training bottlenecks, particularly for the cross-node expert parallelism required by the MoE architecture, and this optimization allowed the cluster to process 14.8 trillion tokens during pre-training with near-zero communication overhead.”
By allowing the routing of tokens to experts and the aggregation of results to be handled in parallel through code called PTX (Parallel Thread Execution), DualPipe helped to drive down costs. The software essentially optimized the hardware. The company also created a 4-node maximum to limit nodes and reduce traffic, allowing for a more efficient communication framework.
MoE models like DeepSeek’s can provide numerous benefits, and this is what DeepSeek is showing – an ability to train larger models at a lower cost with much faster pre-training, faster inference, and an ability to deliver decreased first-token latency. However, MoE also can require higher VRAM to store all experts simultaneously and can face challenges in fine-tuning.
Mixed Point Precision and Multi-Head Latent Attention Lowers Memory Usage
DeepSeek’s success is also found in lowering memory usage with multi-head latent attention that lowered memory usage to 5% to 13%. MLA ultimately reduces memory requirements during inference by processing long sequences of text. As pointed out by ML Engineer Zain ul Abideen, “MLA achieves superior performance than MHA, as well as significantly reduces KV-cache boosting inference efficiency.”
It has been estimated that HBM3e’s component costs in Hopper GPUs could be as much as 25% higher than HBM3-equipped GPUs, and it’s expected HBM4 will add more costs due to the complexities of delivering faster data rates.
Memory is an expensive component and Hopper is known for its limited memory capacity at 80GB of HBM3e memory versus Blackwell’s 192GB of HBM3e (nearly 2.5X the memory in the upcoming release). Therefore, reducing memory usage is one path to optimizing Hopper GPUs.
DeepSeek’s success also stemmed from its pioneering approach to model architecture. The company introduced a novel MLA (multi-head latent attention) method that lowers memory usage to just 5%–13% of what the more common MHA architecture consumes.
Nvidia’s hardware excellence stands out in the Hopper generation of GPUs with the Transformer Engine. Two years ago, Hopper’s transformer engine brought about Chat-GPT’s big moment as the OpenAI model eliminated the need to find patterns between elements mathematically, and this opens up which datasets can be used and how quickly.
The H100s also leverage the transformer engine for mixed precision, such as FP8, FP16 or FP32, depending on the workload. Nvidia architected the ability to switch between floating precision points in order to require less memory usage. Here is what Nvidia states:
“There are numerous benefits to using numerical formats with lower precision than 32-bit floating point. First, they require less memory, enabling the training and deployment of larger neural networks. Second, they require less memory bandwidth which speeds up data transfer operations. Third, math operations run much faster in reduced precision, especially on GPUs with Tensor Core support for that precision. Mixed precision training achieves all these benefits while ensuring that no task-specific accuracy is lost compared to full precision training. It does so by identifying the steps that require full precision and using 32-bit floating point for only those steps while using 16-bit floating point everywhere else.”
DeepSeek says that FP8 allowed it to “achieve both accelerated training and reduced GPU memory usage,” as it validated FP8’s usage for training large scale models for a fraction of the cost. A majority of the “most compute-density operations are conducted in FP8, while a few key operations are strategically maintained in their original data formats,” such as those that require higher precision due to sensitivity reasons.
Though lower-precision training has often been “limited by the presence of outliers in activations, weights, and gradients,” and tests have shown that FP8 training was prone to higher instability and more frequent loss spikes, it is now emerging as a solution for efficient training due to hardware advancements (i.e., Hopper bringing powerful FP8 support, Blackwell bringing FP4).
DeepSeek also provided recommendations for future chips to accommodate low-precision training and replicate this at scale, suggesting chip designs should “increase accumulation precision in Tensor Cores to support full-precision accumulation, or select an appropriate accumulation bit-width according to the accuracy requirements of training and inference algorithms.”
This is what Blackwell was designed to address, with new precisions in Tensor Cores, FP4 precision, increased SM count, and more CUDA cores versus the Hopper. Blackwell also packs 208 billion transistors to provide up to 20 petaflops of FP4, compared to the H100’s 4 petaflops of FP8. The B200 features a second-generation transformer engine supporting 4-bit floating point (FP4), with the goal of doubling the performance and size of models the memory can support while maintaining accuracy.
To simply recreate DeepSeek’s training efficiencies and develop large-scale models, Hopper GPUs are a requirement due to support for FP8, with Blackwell bringing FP4 to power real-time inference and supercharged training for trillion parameter models.
Understanding the nuances of Nvidia’s hardware is the reason that I first called out Nvidia’s AI GPU thesis and CUDA moat in late 2018, and in 2019, Volta’s AI capabilities prompted me to say on my premium stock research site: “I believe Nvidia will be one of the world’s most valuable companies by 2030.” This has led to potential gains of over 4,000% for our free readers.
Blackwell is Not Hopper
This may seem like a moment where AI software is triumphant, yet we are at the end of the Hopper generation with the H100s (and the more restricted H800) GPUs being available for two years now. Two years is eternity in the AI arms race, and the fact Hopper is reaching a point of peak optimization at the very moment that Blackwell is shipping is not a shocking new revelation --- rather, it’s the point of keeping a fast-paced product road map. Per Nvidia’s Computex keynote, from Pascal to Blackwell, their AI systems will deliver “1,000 times increase in AI compute,” while simultaneously decreasing the “energy per token by 45,000X.
Therefore, the market is a bit confused to think the 11X increase in compute from software optimizations is going to catch Nvidia off guard. Below are the stated differences between the H100 and GB200 NVL72 systems on Mixture of Experts (MoE) real-time throughput and training speeds.

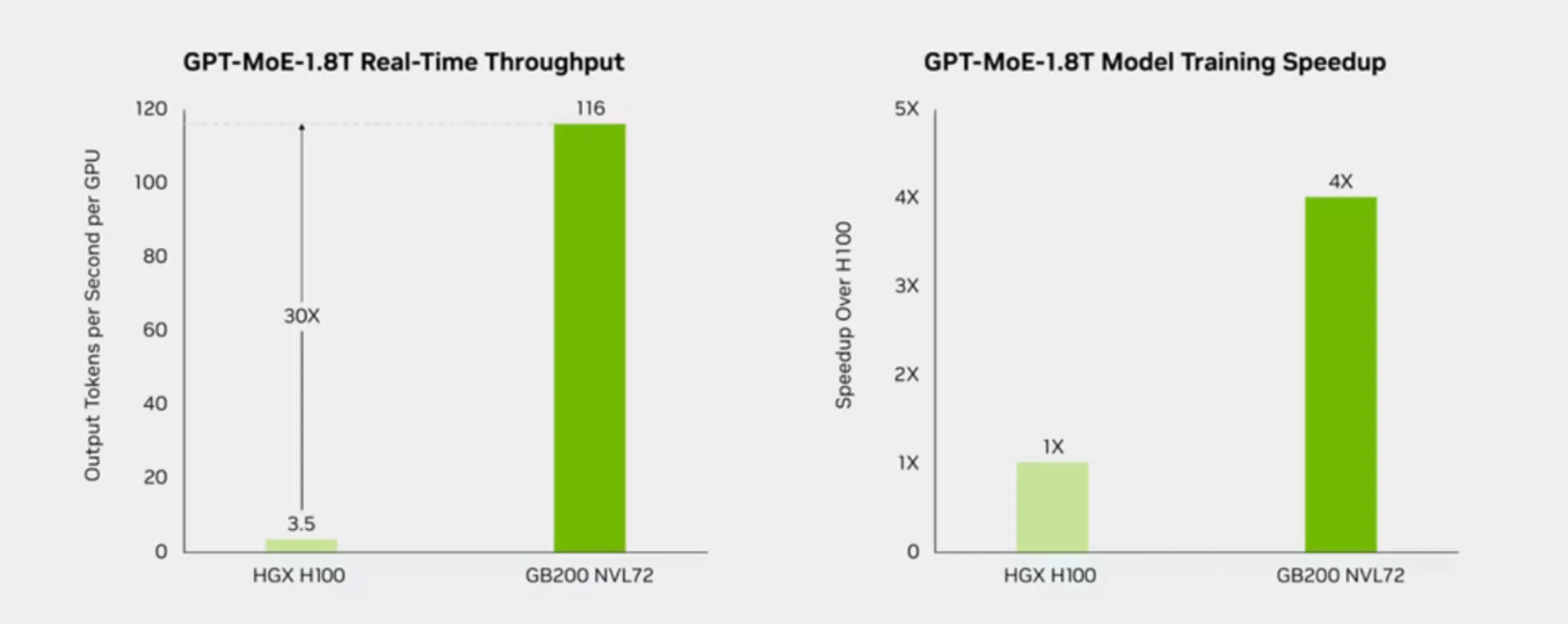
DeepSeek acquiesced the limitations they faced in deploying the model is “expected to be naturally addressed with the development of more advanced hardware.” Note, they are not saying with the development of more advanced software.
I made the point nearly a year ago that Nvidia is competing with Nvidia with its one-year product release road map stating: “The product road map is the single most important thing investors should be focused on. A good chunk of the AI accelerator story is understood at this point. What is not understood is how aggressive Nvidia is becoming by speeding up to a one-year release cycle for its next generation of GPUs instead of a two-year release cycle."
In addition, by open sourcing the model, there will be more developers who can build new AI capabilities. As stated in a Predibase analysis, there were 500 derivative models of DeepSeek created in a few days’ time.
Nvidia has been early to this eventual outcome with the launch of Project Digits, a $3,000 supercomputer that can run 200B-parameter models. By releasing powerful personal computers, Nvidia seeks the proliferation of its GPUs – much like Apple’s iPhone -- whereas companies like OpenAI are the ones most challenged by an open source LLM that drives down input token and output token costs that are 27X less expensive than OpenAI’s o1 model.
Blackwell Inches United States Toward General Artificial Intelligence (AGI)
The reason that software has not officially begun to commoditize hardware, and we could be as far as 5-10 years away from this moment, is because AI development is incredibly nascent. Blackwell and future generations of GPUs are a necessity for AI development to inch closer to the start of general artificial intelligence (AGI).
There have been discussions questioning if it is possible to reach AGI with reinforcement learning: “artificial general intelligence can be achieved if an agent tries to maximize a reward in a complex environment because the complexity of the environment will force the agent to learn complex abilities like; social intelligence, language, etc.”
Reinforcement learning is an ML method where an agent or model learns to make decisions through interactions in its environment, via rewards or punishments. Agents will interact with the environment, receive a positive or negative reward, and adjust its decisions/actions based on the feedback it has received.
AGI refers to the creation of a machine that is capable of performing intellectual tasks on par with humans, and have the ability to understand, learn and apply knowledge to a wide range of domains. Both RL and AGI involve learning from interactions with the environment, though RL is typically more focused on specific tasks or environments where AGI aims to be ‘all-encompassing.’
If software efficiencies from China are relatable to Sputnik, then the arrival of AGI will be the moment we land on the moon. AGI requires an order of magnitude larger models – minimum 1 trillion, up to 10 trillion or more. Reinforcement learning is certainly a step in the right direction, yet trillion+ parameter models are inevitable – and it’ll require Nvidia and other AI accelerator design companies to get there.

Source: DeepSeek R-1 Pictured Above: Nvidia Stock saw its market cap shed $600 billion in one day following DeepSeek’s release with benchmarks surpassing OpenAI on its performance and reasoning abilities.
DeepSeek is Cheap … Or is it?
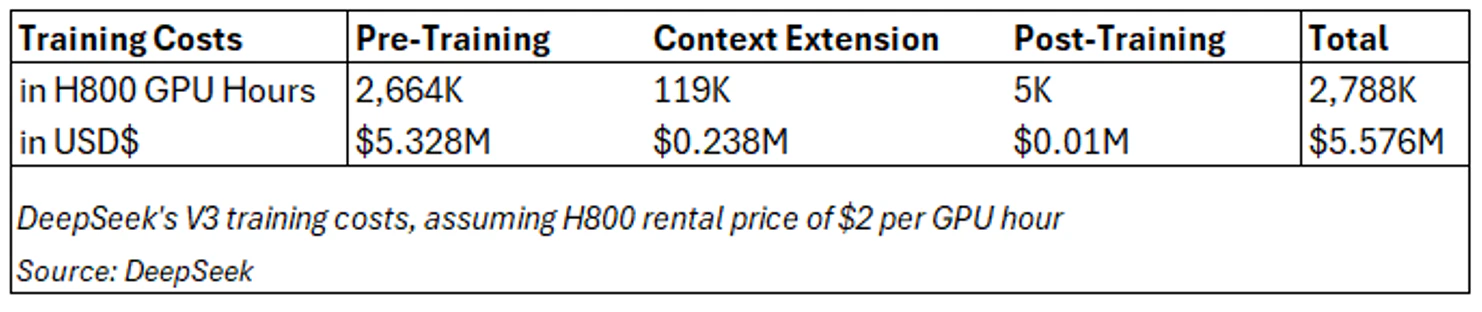
DeepSeek has stated V3 was trained on 14.8 trillion tokens in pre-training, with each 1 trillion tokens taking 180K H800 GPU hours (3.7 days) on its 2,048 H800 cluster. Compare this to Meta’s 405 billion parameter Llama 3.1 model, which was trained in 54 days (30.8M GPU hours) on a 16,384 H100 GPU cluster, estimated to cost ~$80 million at a $2.6/hour rental price.
This accounted for a majority of the costs at $5.328 million, assuming a $2/hour rental price for the H800s (this is about in-line with long-term contract rates at Lambda for the H100, but ~20% lower than short-term costs from other startup cloud providers).
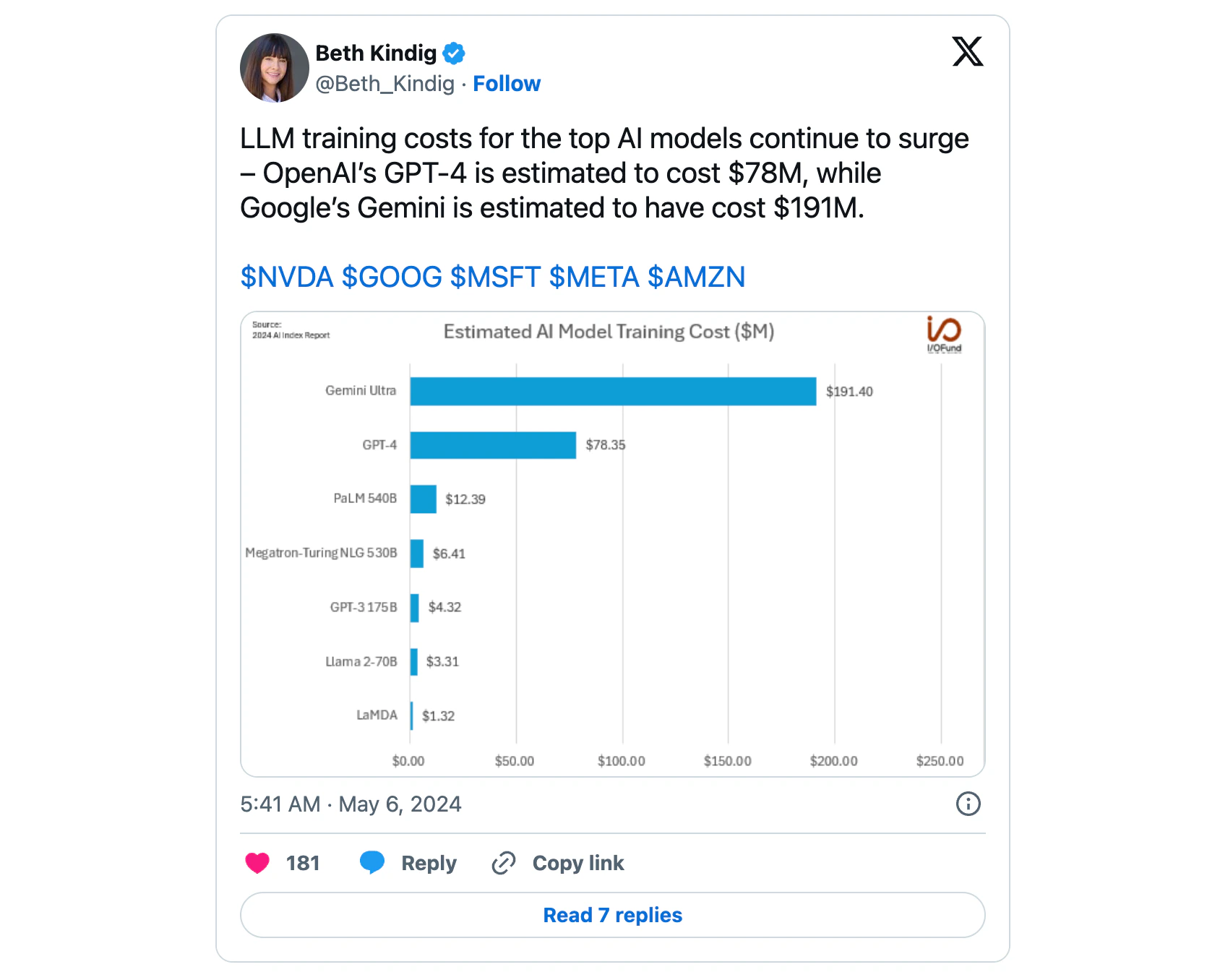
The estimated $6 million cost for DeepSeek would also be pennies on the dollar compared to estimated training costs for OpenAI’s GPT-4 and Alphabet’s Gemini Ultra.


Source: DeepSeek
While the training costs were estimated utilizing rental prices (and up for debate), what’s important to note is that the $5.6 million cost only excluded “costs associated with prior research and ablation experiments on architectures, algorithms, or data.”
Democratization of AI Helps Nvidia
Nvidia’s goal is to not only sell GPUs to the fortresses of Big Tech. Rather, all tech companies seek large addressable markets and the democratization of AI will assist Nvidia in reaching worldwide AI device ubiquity.
In the meantime, Blackwell is sold out. Microsoft stated this week that they are still supply constrained in the cloud, and Azure needs more supply to grow. Meta doubled down on its planned capex for 2025, and signaled a willingness to spend “hundreds of billions” towards AI infrastructure in the long run.
In the medium term, Nvidia will allocate supply to enterprises and edge AI, as lower costs will facilitate enterprise AI and edge computing. The market grew concerned that there would not be ROI on these large AI investments, and on the other hand, the market now is panicking when costs are lowered to the point where ROI can be achieved.
This has always been Nvidia’s goal, with CEO Jensen Huang and other executives declaring at high profile stages such as CES and GTC that the cost of computing will go down with each generation of GPUs. At GTC 2024, Huang explained that Nvidia “accelerated algorithms so quickly that the marginal cost of computing has declined so tremendously over the last decade that it enabled generative AI to emerge. He further explained that reducing the cost of computing and accelerating computing is what Nvidia “does for a living at its core,” and that the “pricing that we create always starts from TCO.”
Nvidia VP Ian Buck corroborated this at BofA GTC Conference in June 2024: “The opportunity here is to help [customers] get the maximum performance through a fixed megawatt data center and at the best possible cost and optimized for cost.”
Sign up for I/O Fund's free newsletter with gains of up to 2600% because of Nvidia's epic run - Click here
What to Monitor for Nvidia’s Earnings Report
There seems to be no end to the amount of Blackwell supply rumors with yet another one circulated in January 2025. According to Taiwan Semiconductor’s management team, “cut the order, that won’t happen. Actually [it will] continue to increase.”
Here are the additional points that cause us to believe Blackwell revenue will show up soon enough:
1) Nvidia CEO Jensen Huang at CES reconfirmed that Blackwell is in full production, adding that “every single cloud service provider now has systems up and running."
2) CFO Colette Kress in Q3’s earnings: “Blackwell demand is staggering and we are racing to scale supply to meet the incredible demand customers are placing on us. Customers are gearing up to deploy Blackwell at scale.”
3) CFO Colette Kress in Q3: “While demand is greatly exceeding supply, we are on track to exceed our previous Blackwell revenue estimate of several billion dollars as our visibility into supply continues to increase.”
4) CFO Colette Kress at UBS’ Global Technology Conference: “What we see in terms of our Blackwell, which will be here this quarter is also probably a supply constraint that is going to take us well into our next fiscal year for several quarters from now. So, no, we don't see a slowdown. We continue to see tremendous demand and interest, particularly for our new architecture that's coming out.” UBS Analyst Tim Arcuri added, “you are actually shipping more Blackwell than you thought you would three months ago.”
5) CFO Colette Kress at CES: “We are able to increase our demand and increase our revenue each quarter as well. … When we think about the demand that is in front of us, it is absolutely a growth year.”
Big Tech’s Capex
Two weeks ago, my firm covered how Big Tech capex (AI spending) came in significantly above expectations in 2024, and is on track to repeat that in 2025. To recap, analysts had initially estimated capex of ~$200 billion for Big Tech in 2024, an increase of ~30% YoY. However, our latest checks suggest that Big Tech is on track to spend at least $236 billion in capex in 2024, 18% higher than analyst estimates and representing YoY growth of more than 52%.
For 2025, Big Tech is on track to spend $300 billion or more on capex, based on initial commitments from Microsoft and Meta totaling at least $140 billion combined. This is already tracking ~7% higher than ~$280 billion estimated by analysts, with Microsoft’s $80 billion commitment 40% higher than estimated and Meta’s $60-65 billion more than 18% higher than estimated.
DeepSeek has highlighted one major tailwind that has been overlooked – if AI models can now be trained quicker and cheaper, it’s likely to catalyze demand for GPU instances in the cloud from leading providers, as GPUs can be rented much faster than setting up new infrastructure. In order to meet elevated demand, hyperscalers will need to continue purchasing, or even accelerate purchasing, Nvidia’s GPUs in order to prevent chip constraints from impeding revenue growth.
Analyst Revisions for Nvidia’s Stock Remain Unchanged
In June 2024, in the analysis Here's Why Nvidia Stock Will Reach $10 Trillion Market Cap By 2030, I discussed the importance of intra-quarter analyst revisions supporting Nvidia’s massive run, as data center revenue continued to blow past expectations.
Seen below, Nvidia’s revenue for FY25 was estimated at $120 billion in June, being revised 31.5% higher over the six months prior. In dollar terms, that represented a nearly $29 billion increase from $91.3 billion. For FY26, revenue was estimated at $157.5 billion in June, a 44.8% increase from $108.8 billion, a nearly $50 billion increase in six months.

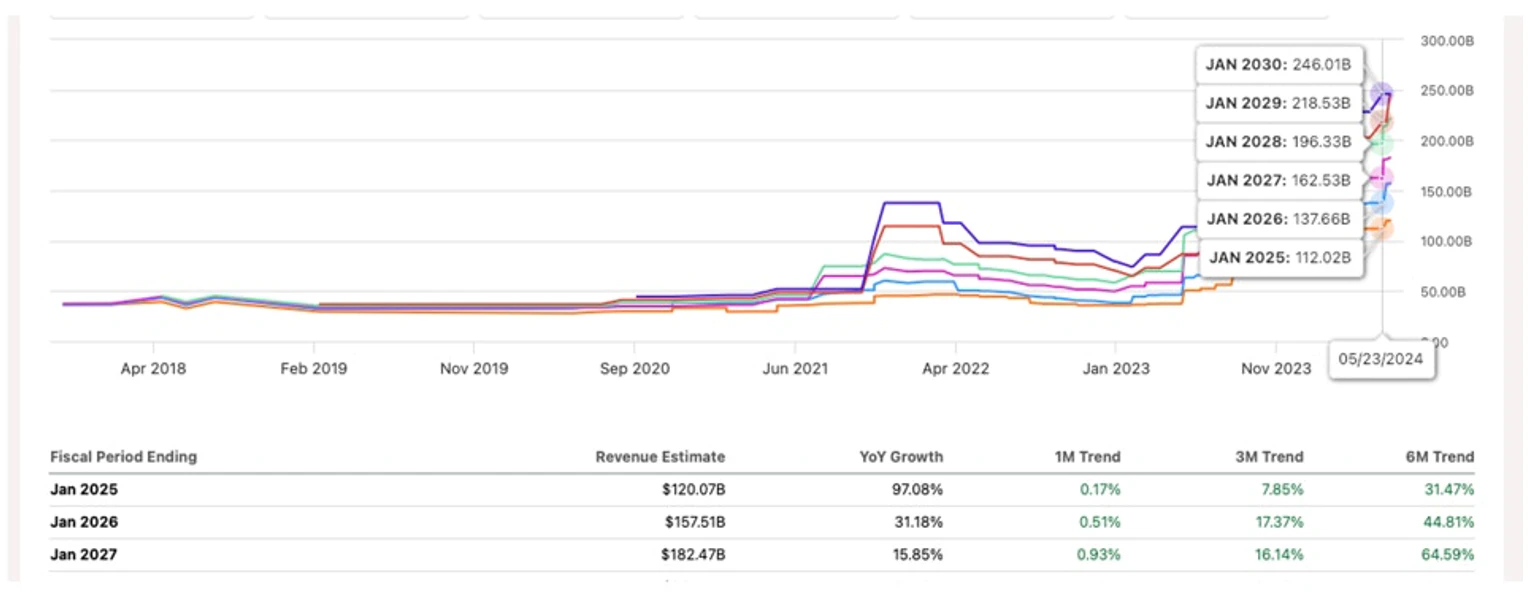
Compare that to today:

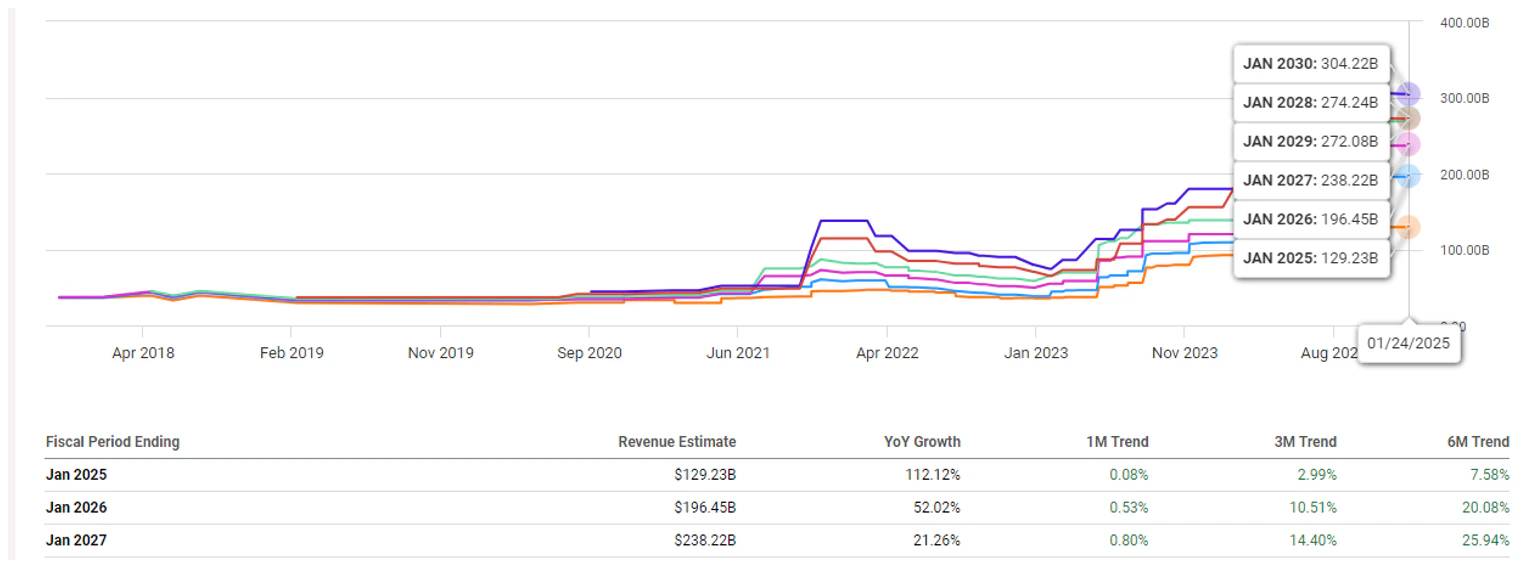
FY25 revisions are up just 7.6% (or $9 billion) since July to $129.2 billion as the fiscal year comes to a close, but FY26 revenue is 20% higher to $196.5 billion. That’s another $39.5 billion (or over a full quarter at the current run rate) that has been added in the past seven months.

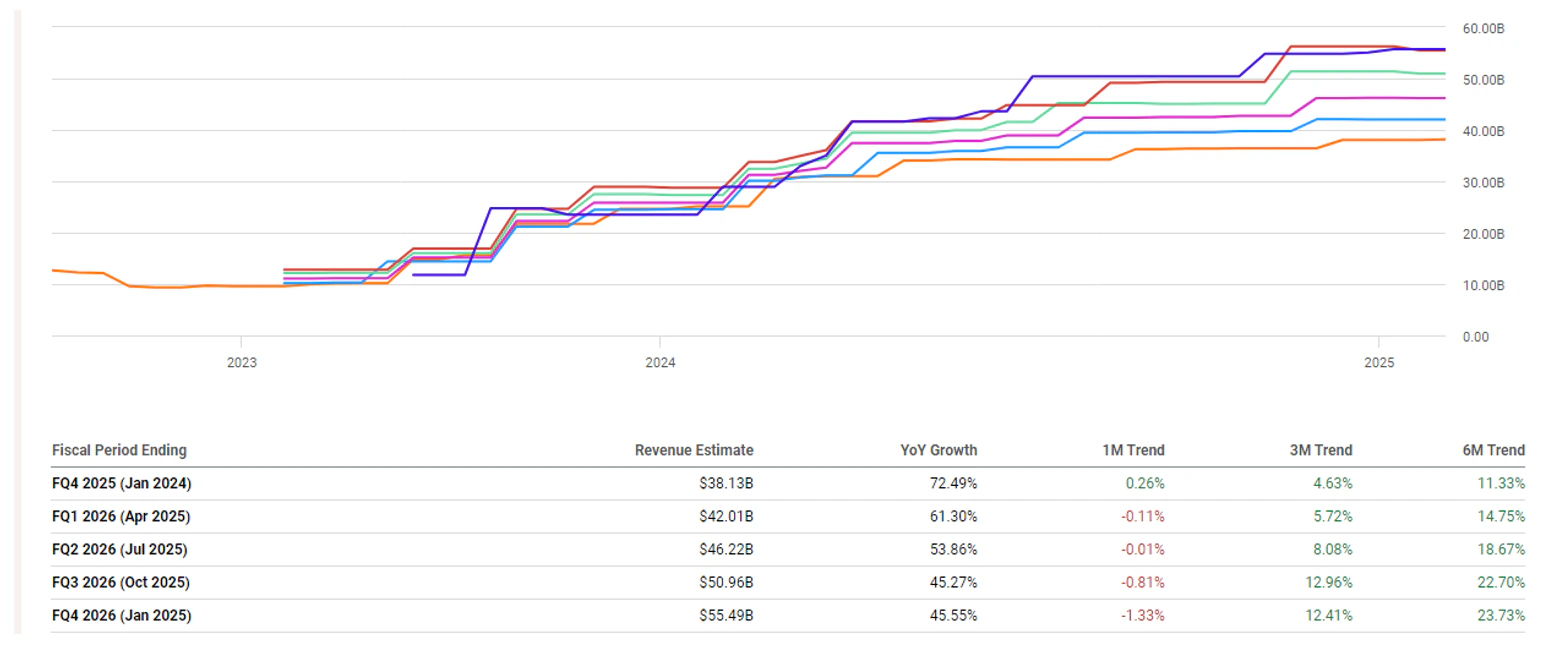
Opinions aside, intra-quarter revisions will be where you will first see any material hiccups or impacts on revenue. FY26 quarterly revisions have come down slightly over the past month, at -1.3% lower for Q4. So far, there has been no impact from DeepSeek’s V3 release – in fact, estimates inched marginally higher on January 28, with Q4 FY26 revenue rising from $55.49 billion to $55.51 billion.
The bigger picture – revenue is still 14% to 24% higher than it was six months ago. At this scale, that’s $6 to $10-billion-plus higher.
Where Nvidia’s Stock Price Goes Next
Let’s talk price targets.
In the write-up “Where I Plan to Buy Nvidia Stock Next” we stated that Nvidia still needs, at least, one more push higher to complete the current uptrend. This would make the volatility that started in June of 2024 a correction within a larger uptrend.
We still believe that NVDA’s uptrend is not over. We stand by the two scenarios outlined in the last report; both are still in play.
“Blue – The final 5th wave is playing out as an ending diagonal pattern, which is common for 5th waves. This type of pattern is a 5 wave pattern in itself that is characterized with large swings in both directions. Our target zone for the bottom on this 4th wave is $126 - $116. If Nvidia can push over $140.75, then then odds favor this scenario.
Red – Nvidia is in a much more complex 4th wave. If this is playing out, NVDA would see the $116 level break, which opens the door to a potential low at $101, $90, or $78.”

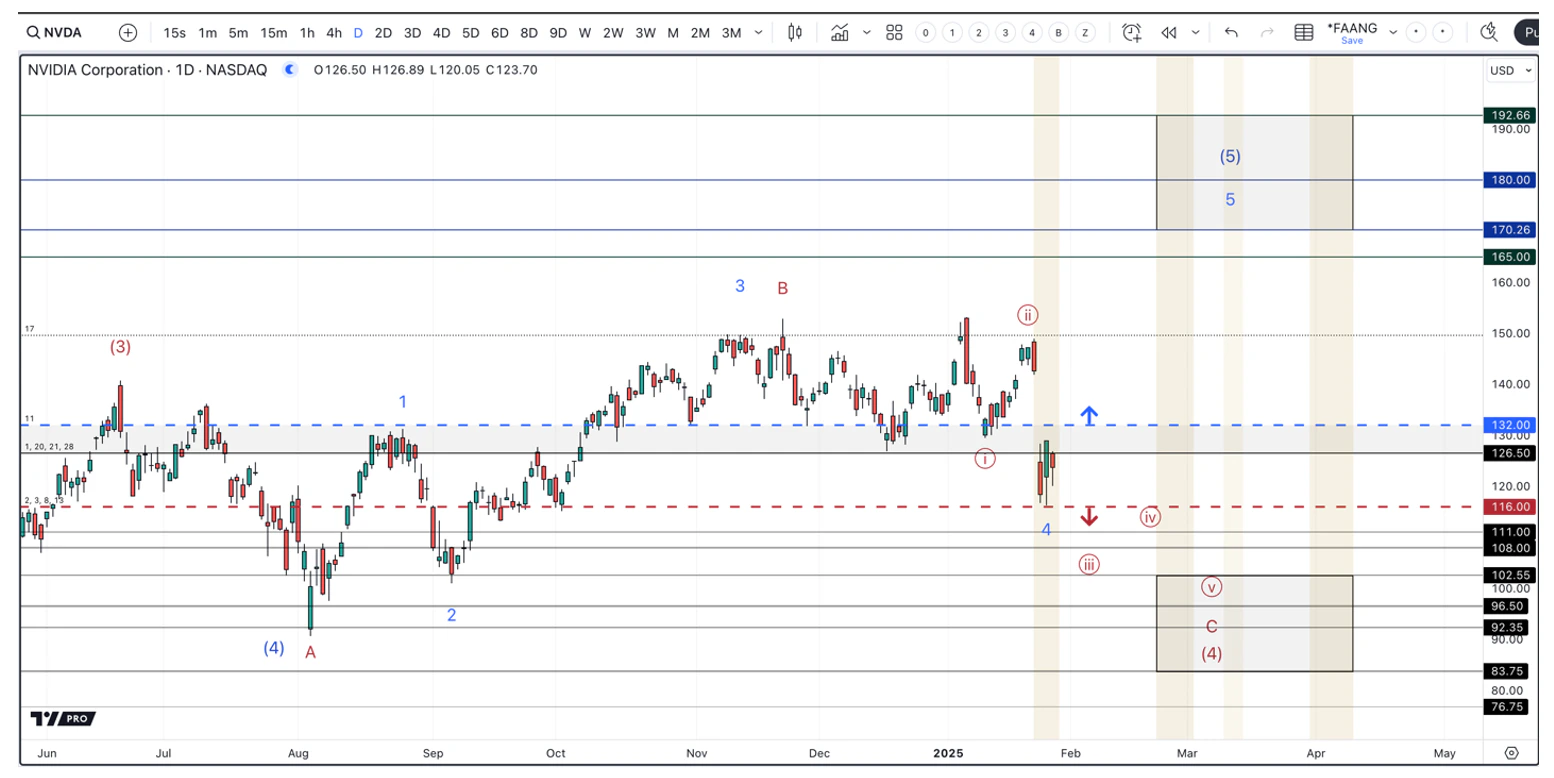
While the $116 support level still holds from our last analysis, the resistance worth monitoring is now $132. If Nvidia can breakout over the $132 resistance, it will shift the odds to the more immediately bullish count in blue. This would see a push into the $170 - $190 region over the coming months.
On the other hand, if Nvidia breaks below the $116 support level, it will signal that the more immediately bearish count in red is playing out. This would see us make a meaningful low in the $102 - $83 range over the coming months.
We began executing on our current buy plan, which is to layer into Nvidia at key levels. The $126 - $116 region was our first target. If the $116 region breaks, we will then target the $102 - $83 region to complete our buying. Considering the blue count is looking for a final 5th wave higher, we will likely not chase a breakout over $132.
Conclusion
If DeepSeek’s breakthroughs are truly the key to ushering in a new paradigm of AI training and ultimately AI democratization from cost reductions, it will not be a death sentence for Nvidia; in fact, quite the opposite.
This is Jevons paradox -- where the technological advancements of Hopper and Blackwell will translate into significant efficiency gains and cost reductions for AI training, that then will drive near-ubiquity for AI services -- and thus increase demand for GPUs in the data center, on-premise for enterprises and also on edge devices.
The market’s readthrough is that Big Tech has now been overspending on AI. However, The I/O Fund believes this readthrough is wrong; it’s not that the United States is overspending, it’s that we will accelerate spending to stay ahead. The I/O Fund recently entered five new small and mid-cap positions that we believe will be beneficiaries of this AI spending war. We discuss entries, exits and what to expect from the broad market every Thursday at 4:30 p.m. in our 1-hour webinar. Learn more here.
Please note: The I/O Fund conducts research and draws conclusions for the company’s portfolio. We then share that information with our readers and offer real-time trade notifications. This is not a guarantee of a stock’s performance and it is not financial advice. Please consult your personal financial advisor before buying any stock in the companies mentioned in this analysis. Beth Kindig and the I/O Fund own shares in NVDA at the time of writing and may own stocks pictured in the charts.
Recommended Reading:




More To Explore
Newsletter

AI Token Demand is Shattering Forecasts
Total annual token processing is no longer measured in billions or trillions of tokens, but in the quadrillions and beyond. As annual token processing is now tracked in units with 15 trailing zeros, i

Nvidia and Google Are Crowding TSMC’s N3 Node - Can Intel Fill the Gap?
Nvidia is moving its next-generation Rubin GPUs from 4nm to 3nm, yet Google’s latest TPUs are already on N3 and are expected to remain there. Meanwhile, a growing number of AI CPUs from Nvidia, Amazon

Intel vs TSMC: How CoWoS Packaging Constraints Could Create an Opportunity for Intel Foundry
Taiwan Semiconductor (TSMC) is the single, most important company to the AI industry. However, to compete with the incumbent, Intel does not need to beat TSMC at leading-edge manufacturing. It only ne
Big Tech’s Free Cash Flow is Turning Negative – Who's Next?
Big Tech’s AI revenue is accelerating, but free cash flow is moving sharply in the opposite direction. Across Google, Microsoft, Meta and Amazon, capex is rising much faster than operating cash flow a
Big Tech Earnings Preview: Is AI Monetization Finally Catching Up to Capex?
The most pronounced difference between 2026’s tech rally compared to rallies in the past is which companies have been left out of it. The names most associated with the AI trade have hardly participat
Nvidia, CXL, and the Battle to Improve AI Inference Economics
This is Part 2 of our two-part series on AI inference economics. In Part 1 — Why Nvidia's Next AI Battle Is About Tokens per Watt, we laid out why tokens per watt has become the defining metric for in

Why Nvidia’s Next AI Battle Is About Tokens per Watt
As hyperscalers move from building AI infrastructure to monetizing it, tokens per watt helps to reflect if revenue is scaling and if profitability is improving. Offload engines can increase tokens per

Micron Is Up 900%. Here’s Why the AI Memory Trade May Still Have Room to Run
Over the past 10 months, memory chip stocks have gone from being solid beneficiaries of the AI boom to capturing a massively outsized piece of the return pie. The inflection in Micron’s performance de

Why the S&P 500 Shrugged Off the Iran War — and What Could Finally Break the Rally
On February 28th, the U.S. went to war with Iran, and the market was handed the kind of shock it hasn't contended with for years. The conflict set off a chain reaction across the region: an ongoing su

Nvidia, CoreWeave, and Nebius: Inside the Circular Financing of the GPU Boom
Neoclouds are one of the more hotly debated AI business models, with CoreWeave and Nebius being the two most widely recognized names. These companies have seen their sales, backlog, and share prices s
